
Doppelte Datensätze in Datenbanken verursachen nicht nur hohe Kosten sondern führen auch zu zahlreichen weiteren Problemen. Nicht zuletzt bei der Konsolidierung verschiedener Datenbestände, z.B. bei Fusion oder Wertschöpfung aus zugewonnenen Daten, ist die Dublettensuche ein unabdingbarer und unternehmenskritischer Prozess. Daher nimmt die Sicherung der Datenqualität im Unternehmen einen immer höheren Stellenwert ein.
Unscharfe Dublettensuche
Beim Auffinden von solchen doppelten Datensätzen muss zwischen scharfen Dubletten (mit genauer Übereinstimmung) und ähnlichen Sätzen unterschieden werden.
Die Gruppierung nach exakten Übereinstimmungen ist etwas, was ein DBMS in wenigen Sekunden ermitteln kann.
Dagegen ist das Aufspüren von ähnlichen Sätzen eine schwierige und rechenintensive Aufgabe, die nur mit Hilfe geeigneter Werkzeuge gelingt. Problem dabei ist, dass ohne geeignete Verfahren noch nicht einmal eingeschätzt werden kann, in welcher Größenordnung die Daten mit solchen Dubletten verunreinigt sind. Man sieht sie einfach nicht.
Auf der Suche nach ähnlichen Sätzen
Schon seit längerer Zeit nutzt man phonetische Algorithmen zur Suche nach ähnlich klingenden Datensätzen (z.B. SoundEx). Dieser Ansatz liefert bereits einige Ergebnisse, die über einen scharfen Vergleich hinausgehen. Dabei bleiben jedoch Permutationen der Zeichenketten (Dreher, Spiegelungen, etc.) unberücksichtigt. Zudem sind phonetische Verfahren sprachabhängig (meist für die englische Sprache optimiert) und legen eine besondere Gewichtung auf den ersten Buchstaben.
Deutlich besser ist da die Nutzung von Mustererkennungsalgorithmen (Pattern Matching, z.B. Levenshtein Distanz). Solche Algorithmen sind in der Lage, Permutationen zu berücksichtigen, sie sind jedoch sehr rechenintensiv.
Ein weiteres Problem stellt die Laufzeit solcher Berechnungen dar: Bei Verwendung von Pattern-Matching Algorithmen muss prinzipiell jeder Satz mit jedem anderen verglichen werden. Daraus ergibt sich für n Sätze die Anzahl von (n - 1) * n / 2 Vergleichen. Das sind dann ½ Billion aufwendige Pattern-Matching Vergleiche bei 1 Mio. Datensätzen. Die Berechnung könnte mehrere Jahre dauern.
Das FuzzyDupes Verfahren

Das FuzzyDupes Verfahren wurde in nun 9 Jahren Entwicklungsarbeit komplett und allein von Kroll-Software entwickelt. Der Rechenkern umfasst über 7.000 Zeilen Code.
Das FuzzyDupes Verfahren nutzt einen Trigram-Hashindex zur Clusterbildung. Dies ist ein mathematisch zuverlässiges und nicht auf phonetischen Algorithmen basierendes Verfahren zur Vorauswahl der Kandidaten für die tiefere Untersuchung mittels eines ebenfalls eigenständig entwickelten Pattern-Matching Verfahrens, welches besser als alle bekannten Verfahren Permutationen berücksichtigen kann.
Die verwendeten Algorithmen basieren auf reiner Mustererkennung, sind daher sprach- und kulturunabhängig und sogar unicodefähig, d.h. Sie funktionieren prinzipiell nicht nur mit lateinischer Schrift. Es ist (bei Kenntnis der Verfahren) mathematisch nachweisbar, dass diese lückenlos und zuverlässig sämtliche Ähnlichkeiten erkennen, ohne dass einzelne Sätze durch ein Raster fallen könnten.
FuzzyDupes 2020 nutzt parallele Ausführung und 64-Bit
Die beiden kritischen Ressourcen bei der Dublettensuche sind Speicherbedarf und Rechenzeit.
Bei großen Datentabellen hat das Verfahren einen recht hohen Arbeitsspeicherbedarf (RAM), der nur auf 64-Bit Systemen zur Verfügung steht. 32-Bit Systeme können maximal nur 2,4 Gigabyte Speicher adressieren.
Mit größerem Entwicklungsaufwand konnte das Verfahren zudem parallelisiert werden. Dadurch werden Multi-Prozessor und Multi-Core Systeme voll ausgenutzt und das Verfahren skaliert sehr gut mit der Anzahl der zur Verfügung stehenden Prozessoren.
Die aktuelle Version von FuzzyDupes erlaubt also die Suche in immer größeren Datenbeständen mit heutigen standard PC's.
Warum ist FuzzyDupes so preiswert im Vergleich zu manchen anderen Dublettensuch-Programmen ?
Dublettensuche war in der Vergangenheit eine Speziallösung für einen sehr begrenzten Kundenkreis. Zudem waren das Anwendungen für Großrechner, da nur diese in der Lage waren, den Rechenaufwand zu leisten. Daher waren solche Programme sehr teuer.
Wir sind jedoch der Meinung, dass eine unscharfe Dublettensuche für jedes Unternehmen unverzichtbar ist, welches eine Kundendatenbank pflegt. Wir wollen diese Anwendung auch für kleinere und mittlere Unternehmen nutzbar machen, wobei uns bewusst ist, dass der Preis immer in einem Verhältnis zum Nutzen stehen muss. Daraus kalkuliert sich unser Preis. Wobei der Nutzen für Ihr Unternehmen um ein vielfaches über dem Preis einer FuzzyDupes-Lizenz liegen kann.
Warum ist die Demo-Version funktional völlig unbeschränkt ?
Wir haben in der Vergangenheit gesehen, dass es schwer ist, neue Anwender von der Notwendigkeit einer Dublettensuche zu überzeugen, wenn die Demo-Version zu sehr eingeschränkt ist.
Wir sind der Meinung, dass stark eingeschränkte Demo-Versionen niemandem helfen. Daher können Sie in unserer aktuellen Demo das Programm in vollem Funktionsumfang testen und das komplette Suchergebnis beurteilen.
Bitte beachten Sie: Wir stellen Ihnen diese kostenlose Demo ausschließlich zu Evaluierungszwecken zur Verfügung. Damit Sie prüfen können, ob diese Software das leistet, was sie verspricht, und um zu prüfen, ob Sie überhaupt einen Bedarf an einer solchen Dublettensuche haben.
Schon die Nutzung der Suchergebnisse erfordert jedoch eine kostenpflichtige Lizenz. Wir nennen das "Faire Software". Bitte seien Sie fair und lassen Sie diese Software lizensieren, wenn Sie sie produktiv einsetzen wollen.
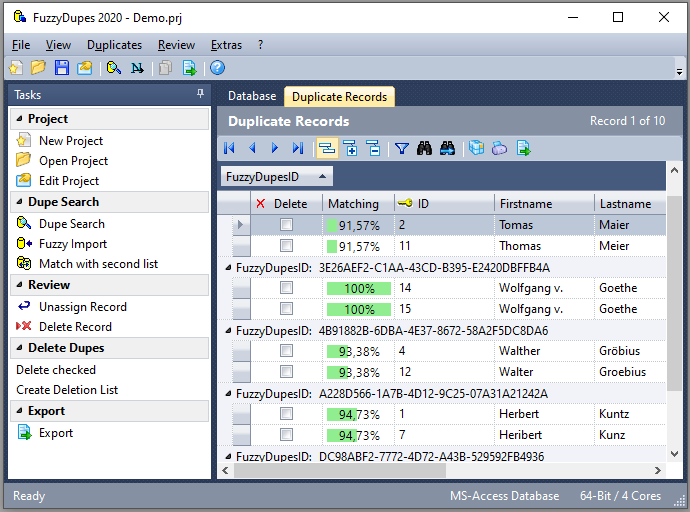
Beispiel Suchergebnis

Features
Grundlegende Features
- Schnelle unscharfe Dublettensuche in vielen Datenquellen
- Unscharfes Zusammenführen von zwei Listen
- Unscharfer Abgleich mit externer Liste
Neu in der FuzzyDupes Version 2020
- Deutlich höhere Leistung und Geschwindigkeit durch parallele Ausführung und 64-Bit
- Dadurch praktisch unbegrenzt große Datenmengen durchsuchbar
- Volle Ausnutzung moderner Core-iX Prozessoren und 64-Bit Systemen
- Nutzt DotNet 4.0 Framework (auf den meisten Computern bereits installiert)
- Anzeige der Übereinstimmung im Suchergebnis
- Zugriff auf MS-Access und MS-Excel Daten auch unter 64-Bit
- Zusätzlicher 32-Bit Launcher für den Zugriff auf 32-Bit Datenquellen
Unterstützte Datenbankformate:
- MS-Access, MS-Access 2007* und 2010*
- MS-Excel, MS-Excel 2007* und 2010*
- MS SQL-Server
- Text/CSV Dateien
- Andere Datenbanken mit ODBC-Treiber oder OLEdb Provider, z.B. Oracle, IBM DB2, MySQL, dBase, Foxpro, Paradox, FileMaker, Cache, PostgreSQL, etc.
- Suche und Löschen aus MS-Outlook Kontaktordnern.
FuzzyDupes ist somit die Lösung zum Beseitigen von Dubletten aus Outlook. - Windows Adressbuch
- MS-SharePoint Server
- BulkMailer Adressdatenbanken
- 32-Bit Datenquellen können mit Hilfe des FuzzyDupes 32-bit Starters verwendet werden
 64-bit ODBC data sources
64-bit ODBC data sources
- Windows Contacts / Windows Mail
*) Erfordert Installation der Microsoft Access Database Engine, falls noch nicht vorhanden.
Download
Systemanforderungen
- Windows XP bis Windows 10 (32 und 64-bit)
- Microsoft DotNet Framework 4.0 oder höher (auf den meisten Computern bereits installiert)
- Ausreichend freier Arbeitsspeicher bei großen Datenbanken
Version 9.0.0
Sie können im Menü Extras aus 25 Sprachen wählen: český, danske, deutsch, ελληνικά, english, español, eesti, suomalainen, français, हिंदी, hrvatski, magyar, Icelandic, italiano, 日本人, Nederlands, norsk, português, русский, slovenský, slovenščina, svenska, ภาษาไทย, Türkçe, 中国的
Bestellung
Sie können FuzzyDupes 2020 kostenlos und unverbindlich 30 Tage lang testen. Danach müssen Sie eine Nutzungslizenz erwerben, wenn Sie das Programm weiterhin verwenden wollen.
Eine Einzelplatzlizenz kostet € 349.00 netto*
*) Die angegebenen Preise sind Nettopreise. Ob und wieviel MwSt. Sie zahlen müssen ist davon abhängig, wie und aus welchem Land Sie bestellen. Weitere Informationen dazu finden Sie auf der Shop Seite
Die Lizenz berechtigt zum zeitlich unbegrenzten Einsatz der Software an einem Arbeitsplatz. Es enstehen keine weiteren Kosten. Kostenlose Updates auf alle Versionen 8.x und kostenloser Support inbegriffen.
FuzzyDupes 2020 Bestellung

Sichere Zahlung per Kreditkarte, Überweisung oder PayPal
über die Firma Share-it Digital River GmbH, Koeln
Firmen aus der EU und der Schweiz können auch gegen Rechnung bestellen.
Uns genügt eine formlose Bestellung per Email an bestellung@kroll-software.ch.
Bitte geben Sie dabei Ihre vollständige Rechnungsanschrift an.
Updates
Das Update ist für registrierte User der Version 5.x, 6.x und 7.x kostenlos, wenn Ihre Lizenz von nach dem 01.01.2010 stammt.
Ansonsten ist ein Update zu EUR 174,- verfügbar.
Wenn Sie unsicher sind, fragen Sie bitte nach dem Update. Wenn Sie sicher sind, bestellen Sie
hier
Wenn Sie Fragen zu diesem Produkt oder zur Bestellung haben,
zögern Sie nicht, uns anzurufen. Wir beraten Sie gern
unter Tel.: +41-41-5351767 (Schweiz)
Vielleicht finden Sie Ihre Fragen bereits beantwortet
in den FuzzyDupes 2020 FAQ's
Noch mehr Info's zu FuzzyDupes 2020 finden Sie in der Online Hilfe.
FuzzyDupes 2020 ist auf zahlreichen Download-Sites gelistet und bewertet, unter anderem:

