
Duplicate records in databases do not only cause high costs, they can also lead to many other problems. Not least when consolidating different data inventories, e.g. during fusion or adding value from acquired data, the duplicate search is an indispensable and critical business process. This is, why data quality more and more becomes a significant value for every business.
Fuzzy Duplicate Search
When searching for such duplicate records, you must distinguish between sharp (with exact accordance) and similar duplicates.
Grouping for exact matches is something, what any DBMS can do in seconds.
On the other hand is the detection of similar records something, that can be hardly achieved and what is computationally intensive. This only succeeds with specialized tools. A problem is, that without the capable methods you cannot even estimate, in which dimension such duplicates exist in your data. You just can't see it.
On the Search for similar Records
Over years, phonetic algorithms (e.g. SoundEx) are used to find what sounds similar. This approach already brings up some results, which go beyond any sharp comparison. Thereby permutations of the strings (like twisting and mirroring) stay unconsidered and a too strong emphasis is layed upon the first letter.
Much better is the use of pattern-matching algorithms (e.g. Levenshtein Distance). Such algorithms can consider permutations, but are highly calculation cost intensive.
So another problem is the total running time of the calculation: When using pattern-matching algorithms, in principle each record must be compared with each other. This means for n records the total number of (n - 1) * n / 2 comparisons. That are ½ trillion (1012) complex calculations for a datatable with 1 million records. The calculation could last for years.
The FuzzyDupes Method

The FuzzyDupes method was developed within 9 years by now, completely and originally done by Kroll-Software. The calculation kernel contains more than 7.000 lines of code.
FuzzyDupes makes use of a Trigram-Hashidex for building clusters. This is a mathematical exact and reliable way to preselect good candidates for the deeper search, which does not depend on phonetical algorithms. The deep search pattern-matching algorithm was also developed by Kroll-Software and it can better consider all permutations than any other known algorithm.
All used algorithms are based completely on pattern-matching and are therefore language- and culture independent. Unicode is fully supported and so this works not only with latin characters. It is mathematically verifiable, that all similarities are detected consistently and reliably.
FuzzyDupes 2020 uses parallel Execution and 64-bit
The two critical resources for the duplicate search application are memory usage and calculation time.
With large data tables, the process has a high demand on RAM, which can only be allocated on 64-bit systems. 32-bit systems can only address a maximum of 2,4 gigabyte of memory.
We put in much development effort to parallelize the algorithms and unleash the power of modern multi-core cpu's. FuzzyDupes scales very good with the number of cores.
So the current version offers the search in bigger data tables on todays standard computers.
Why is FuzzyDupes so affordable compared with other duplicate search software ?
Duplicate search programs used to be specialized solutions and the preserve of a very limited clientele. In addition, these applications could only be run on mainframe computers due to the high computing power required. As a result, the applications were very expensive.
We believe that the ability to perform fuzzy duplicate searches is crucial for every company maintaining a customer database. We want to make our application accessible to small and medium sized enterprises and recognize that the price must stand in direct relation to the benefit gained. These considerations form the basis for the price of our product. However, the benefit for your company can far exceed the cost of a FuzzyDupes license.
Why does the new demo version offer full functionality ?
We have learned from experience that it is difficult to persuade new users of the necessity of a duplicate search if the demo version is too limited. Until now, we have only issued full-featured versions on request.
However, we believe that a demo version that is too limited is of no use to anybody. With this in mind, our latest demo version allows you to try out the full functionality of the program and assess a complete list of search results.
Please note: This free demo version is supplied for trial purposes only as a means of helping you to decide whether the application lives up to its claims and whether or not you have a need for a duplicate search program.
To use the search results, you will need to purchase a license. We call this "fair software". Please be fair and obtain a license for this software if you wish to use it in a productive environment.
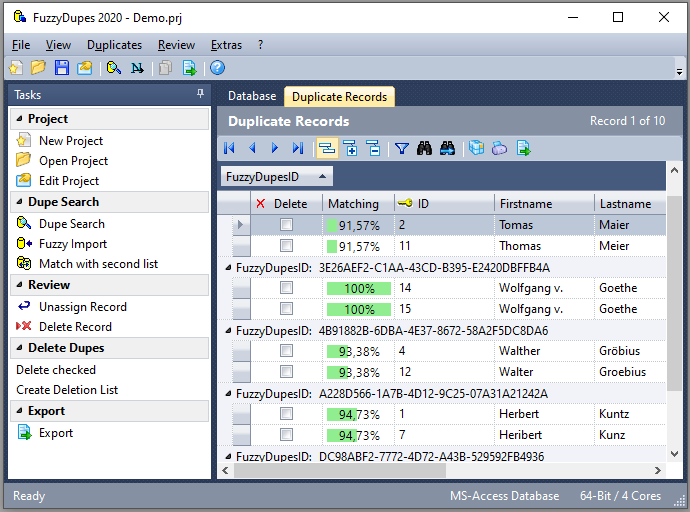
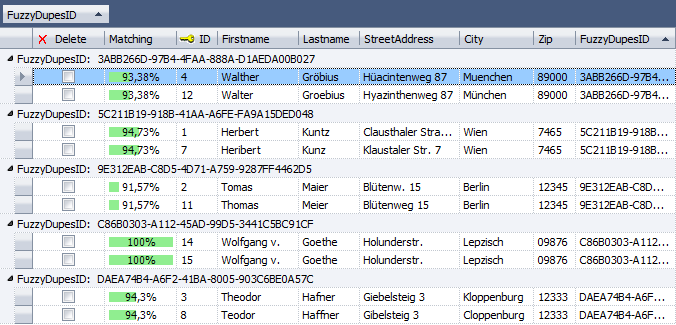
Sample Search Result
Features
General Features
- Fast fuzzy duplicate search in many data sources
- Fuzzy merge of two lists
- Fuzzy match with external list (Robinson list)
New in FuzzyDupes Version 2020
- Notebly higher power and speed through parallel execution and 64-bit
- Thereby practically unlimited size of data searchable
- Full usage of modern Core-iX cpu's and 64-bit systems
- Uses DotNet 4.0 Framework
- Display of the match-factor in the results
- Support of MS-Access and MS-Excel data sources even on 64-bit systems
- The new 32-bit launcher offers access to 32-bit data sources on 64-bit systems
Supported Data Sources / DBMS:
- MS-Access, MS-Access 2007* and 2010* on 32-bit and 64-bit systems
- MS-Excel, MS-Excel 2007* and 2010* on 32-bit and 64-bit systems
- MS SQL-Server
- Text/CSV Files
- Other Datasources with ODBC-Driver or OLEdb Provider, e.g. Oracle, IBM DB2, MySQL, dBase, Foxpro, Paradox, FileMaker, Cache, PostgreSQL, etc.
- Search and deletion from MS-Outlook contact folders.
This makes FuzzyDupes the solution for cleansing Outlook contacts - Windows Addressbook
- MS-Sharepoint Server
- BulkMailer Address Database
- 32-bit data sources can be accessed on 64-bit systems using the FuzzyDupes 32-bit launcher
 64-bit ODBC data sources
64-bit ODBC data sources
- Windows Contacts / Windows Mail
*) Requires installation of the Microsoft Access Database Engine, if not already installed.
Download
System Requirements
- All current versions of Windows
- Microsoft DotNet Framework 4.0 or above (already installed on most computers)
- Enough of free memory (RAM) for large databases
Version 9.0.0
In menu Extras you can choose from 25 languages: český, danske, deutsch, ελληνικά, english, español, eesti, suomalainen, français, हिंदी, hrvatski, magyar, Icelandic, italiano, 日本人, Nederlands, norsk, português, русский, slovenský, slovenščina, svenska, ภาษาไทย, Türkçe, 中国的
Order
You can test FuzzyDupes 2020 for free and with no obligation for 30 days, after which you are required to obtain a usage license, if you want to continue using the program.
A single work-station license costs € 349.00 net amount*
*) All prices are net amounts. If and how much VAT you have to pay depends on how and from where you place your order. More information can be found on the Shop Page
The license permits to use the software at one work station for an unlimited duration. There are no further costs. The price includes free updates to all versions 8.x and free support by email or phone.
Order FuzzyDupes 2020

Secure payment by credit card, bank transfer or PayPal
via the company Share-it Digital River GmbH, Koeln
Updates
The update is free for registered users of version 5.x, 6.x and 7.x, if you ordered the software after Jan. 1, 2010.
If your license is older, you can order an update license for EUR 174,-
if you are not sure, please ask for the update. If you are sure, please order your update
here.
If you have any questions regarding this product or the ordering process,
please don't hesitate to contact us
by email or phone: +41-41-5351767 (Switzerland)
You may find your questions already answered
in the FuzzyDupes 2020 FAQ
You can find even more information about FuzzyDupes 2020 in the Online Help.
FuzzyDupes 2020 is listed and rated on many download-sites, among others:


Dedupe, Data Cleansing, Data Quality, Record Linkage
Software to find and remove duplicate data records is also known as dedupe or data cleansing software.